Machine translation in game localization cannot be fairly evaluated with a single universal metric—you need different tools for different jobs. At Allcorrect, we combine an automated LISA/MQM‑based scoring system, edit distance plus embeddings, and classic metrics like COMET/chrF to both measure post‑editing effort and control raw MT quality. This hybrid approach works best for creative game content.
Content:
- The Quest for the “Perfect” Score
- How We Measure MT Quality in Game Localization
- Why don’t BLEU and COMET solve production problems?
- Can reference-free quality estimation fix this?
- How can we measure linguists’ effort with edit distance and TER?
- Do embeddings finally give us a smart, language-agnostic score?
- Our solution: “Atomic” approach
- How do we actually combine all these metrics in our daily pipeline?
- FAQ
When you start using machine translation (MT) and AI in localization, you inevitably hit a wall. It’s the wall of The Big Question: Is this translation actually any good?
That question triggers a spiral of existential dread: What is “good”? What is “bad”? How do I choose the best engine? Why is this happening to me?
In an ideal world, the answer would be simple. You’d think, “Hey, there are dozens of standard metrics out there—just pick one!” But in game localization, nothing is ever that easy.
We’ve spent a lot of time down this rabbit hole. We’ve tested standard metrics, experimented with embeddings, and analyzed the results against real-world game files. In the end, we had to build our own solution based on LISA and MQM frameworks.
Instead of chasing a single “perfect” score, we ended up designing a multi‑layered approach tailored specifically to video game content.
Here is the story of our journey through the alphabet soup of MT metrics—and what we found works best for video games.
Why don’t BLEU and COMET solve production problems?
If you Google “MT quality metrics,” these are the first two you’ll see.
- BLEU: The grandfather of metrics. It compares the machine translation to a “gold standard” human translation, focusing on accuracy—basically, word and phrase matching.
- COMET: The modern benchmark. Unlike BLEU, it doesn’t just match words. It compares the meaning of the source and the translation according to the reference. It understands context and synonyms—so it knows that “car” and “auto” are essentially the same thing, giving you a much fairer score.
The problem: These metrics are great for a laboratory. If you want to compare Engine A vs. Engine B on a test dataset, they work just fine.
But what about real production? They have a fatal flaw: They require a human reference translation.
Think about it. We use AI/MT to save time and budget. If we already have a perfect human translation to compare against, why are we running MT? The goal of MT is to generate a translation before a human even sees the source text.
Sure, you can measure it post factum by using the final, post-edited text as the “reference.” But that’s looking in the rearview mirror. It doesn’t help you decide now whether a specific engine is struggling with your specific UI text or dialogue.
Can reference-free quality estimation fix this?
So, we looked at reference-free metrics like CometKiwi. These evaluate quality based on pretrained parameters without needing a human translation to compare against. This sounds perfect for industrial scale—just feed in the files and get a score!
The game loc problem: When we tested this on game files, the results were… awkward. Games are full of slang, creative writing, tags, and variables. We found that these metrics often penalized good translations because they weren’t “literal” enough.
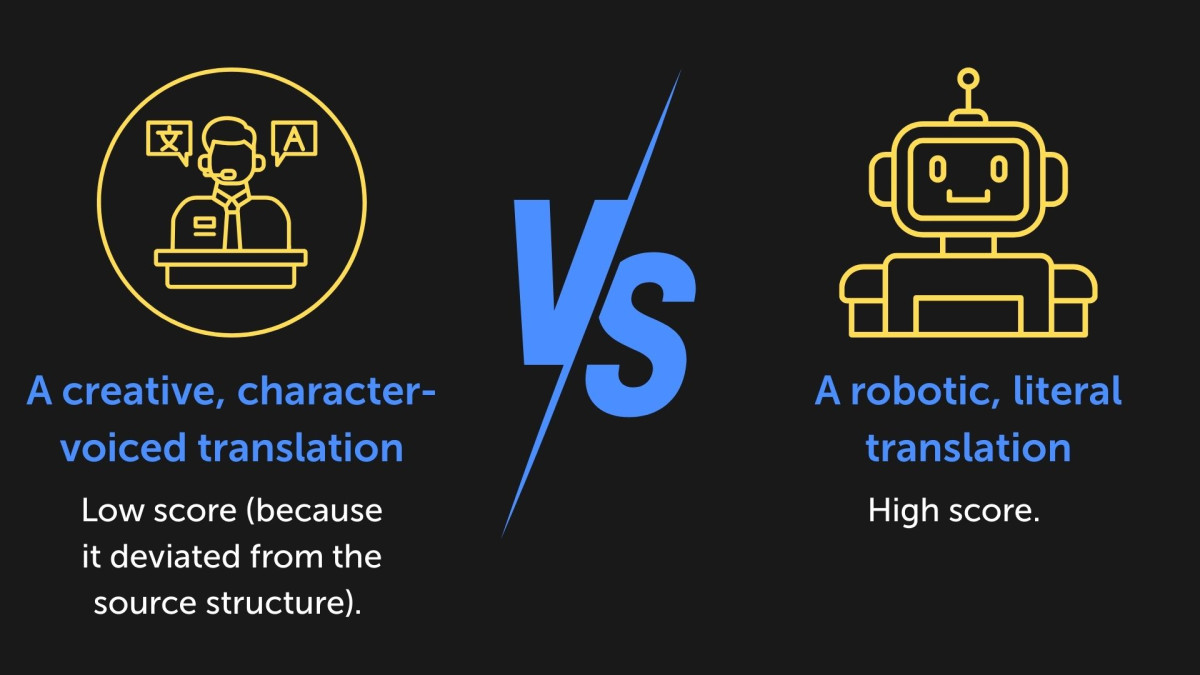
It might work for a washing machine manual, but for game localization, it’s not reliable enough to be a “set it and forget it” tool.
In other words, reference‑free QE is a promising idea, but in the messy reality of game dialogue, jokes, and character voice, it can easily reward the wrong things.
How can we measure linguists’ effort with edit distance and TER?
If we can’t predict quality perfectly, can we at least measure how hard our linguists are working? Enter edit distance and TER.
- Edit distance (Levenshtein): This counts the character-level changes (insertions, deletions, typos) needed to turn the MT output into the final text. It gives us a raw, mechanical count of how much the text physically changed during editing.
- TER (translation error rate): This is the evolved version. It looks at word-level changes and, crucially, includes “shifts” (moving a sequence of words to a different part of the sentence).
The difference: While edit distance is a raw count of character changes, TER gives us a percentage of the text that needed fixing.
- Edit distance = “You changed 50 characters.”
- TER = “You had to rewrite 30% of the sentence structure.”
The verdict: These are incredibly useful, but again—they are post-mortem tools. They tell us how much work was done, but they leave the initial quality of the raw output a mystery until the job is finished.
So, edit distance and TER are great for quantifying post‑editing effort and productivity, but they still can’t tell in advance whether the MT was good enough in the first place.
Do embeddings finally give us a smart, language-agnostic score?
This is where things get nerdy. In a broad sense, an embedding turns data (text, images, sound) into vectors—sets of numbers.
Imagine a 3D room. If the words “cat” and “kitten” have similar meanings, their numbers (coordinates) will place them in the same corner of the room. If the translation is accurate, the source text and the target text should sit in roughly the same spot in that mathematical room.
-
The theory: Measure the distance between the source vector and the target vector. High similarity = good translation.
- Pros: Fast. Cheap (token-wise). No human reference needed. Language agnostic.
The reality in gaming: We really wanted this to work.
We hoped for a “traffic light” system:

It didn’t work.
In game localization, we often do transcreation. If a character quotes a culturally specific song in English, we might replace it with a completely different, culturally relevant song in the target language. The vibe is perfect, but the semantics (the vectors) are totally different. Conversely, a literal, soulless translation often gets a high similarity score because it matches the words, even if it missed the joke.
The silver lining: However, we found a cool use for embeddings: measuring the “depth of editing.” By comparing the similarity of the raw MT vs. the final human edit, we can see how much the meaning shifted. Combined with edit distance, this tells us if the linguist just fixed typos (high edit distance, minimal vector shift) or completely rewrote the meaning (high vector shift).
Our solution: “Atomic” approach
After trying everything, we realized we didn’t just need a “score” or “prediction.” We needed to know what was wrong.
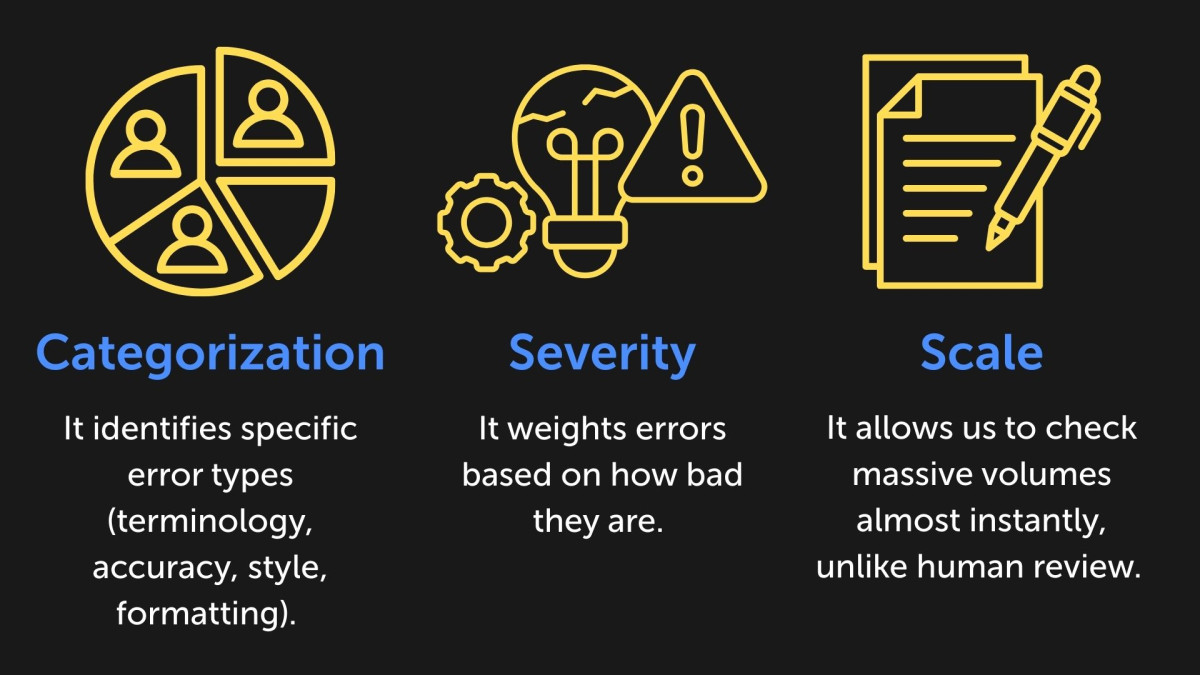
We realized that the classic human evaluation standards (like LISA or MQM) had the right idea: detailed error categorization, severity levels, and penalty weights. They were just too slow for modern volumes.
So, we automated them.
We developed our own AI-powered scoring tool that applies these strict industry standards at scale. It doesn’t just guess. It scans the text to identify specific errors, classifies them by type and severity, and calculates a final quality score based on “penalty points” per 1,000 words.
Instead of a vague “85% similarity,” we get an atomic assessment:
How do we actually combine all these metrics in our daily pipeline?
So, what’s the answer to “How do you evaluate quality?”
The answer is: Use the right tool for the job.
We use a hybrid pipeline:
- 1. Our proprietary scoring: For the daily grind. It gives us an initial quality check, identifies specific error types, and helps us spot bad batches before they hit the editors.
- 2.Edit distance + embedding dynamics: To measure the effort required for post-editing (MTPE) and analyze how much the text “evolved” during the process.
- 3. COMET/chrF: For specific R&D tasks when we need to compare raw engine performance on test kits.
Metrics are just instruments. In the creative chaos of game localization, you can’t rely on just one. You need a full orchestra.

1. What is the main problem with BLEU and COMET in real game production?
BLEU and COMET require a human reference translation, which defeats the purpose of using MT to save time and budget before human editing begins. They are great for lab comparisons but don’t help decide in real time if an engine handles your game’s UI text or dialogue well.
2. Can reference-free metrics like CometKiwi work for game files?
Reference-free quality estimation like CometKiwi sounds ideal for scale, but it often penalizes creative game translations that deviate from literal source structure. Robotic literal translations score high, while character-voiced creative ones score low—unreliable for slang-heavy, transcreative game content.
3. How does edit distance differ from TER, and when to use each?
Edit distance counts raw character changes (insertions, deletions) to turn MT into final text, while TER measures word-level changes as a percentage, including shifts in word order. Use edit distance for mechanical volume of edits and TER for understanding structural rewrites needed.
4. Why don’t embeddings give a simple “good/bad” score for game localization?
Embeddings measure semantic vector similarity between source and target, but transcreation (e.g., replacing a cultural song reference with a local equivalent) shifts vectors too much, even if the vibe is perfect. Literal translations score high despite missing jokes or voice.
5. How can embeddings still be useful for MT evaluation?
Compare the embeddings of raw MT to the final human edit to measure the “depth of editing.” A minimal vector shift with high edit distance means typo fixes, while a larger shift indicates a full meaning rewrite. This reveals how much MTPE truly evolved the content.
6. What is the “atomic” approach Allcorrect uses for MT scoring?
We automated LISA/MQM frameworks into an AI tool that scans text for specific error types (terminology, accuracy, style, formatting), assigns severity weights, and calculates penalty points per 1,000 words. It provides a detailed error map, not just a vague percentage.




